

Семантическое ядро – костяк, который помогает понять, как раскрыть тему наиболее полно и продвинуть страницу в топе выдачи. Мы прежде всего ищем, что пользователи вбивают при поиске в Яндексе. Есть правила сбора СЯ для текста – о них и поговорим. Вы сможете руководствоваться этими правилами, даже если не являетесь сеошником. Поэтому скорее читайте, как собрать семантическое ядро для статьи, и приступайте! 🙂
Обратите внимание:
- Процесс парсинга СЯ для коммерческих и информационных статей отличается. В этом тексте мы осветим именно инфотексты.
- Есть несколько подходов к сбору ядра. Каждый собирает по-разному, и единого подхода нет. Мы расскажем только об одном из них.
Погнали!
Подписывайся на наш Телеграм канал и узнавай все самое интересное первым!
1. Собираем семантическое ядро
Сбор семантического ядра проходит в несколько этапов. Прежде чем приступить к парсингу, определимся, стоит ли использовать для этого специальную программу.
Есть разные сервисы для сбора ключевых слов и фраз. Самый популярный онлайн-сервис – Яндекс.Wordstat. Он хорош, если ключевиков по вашей теме не так много. Вот пример:
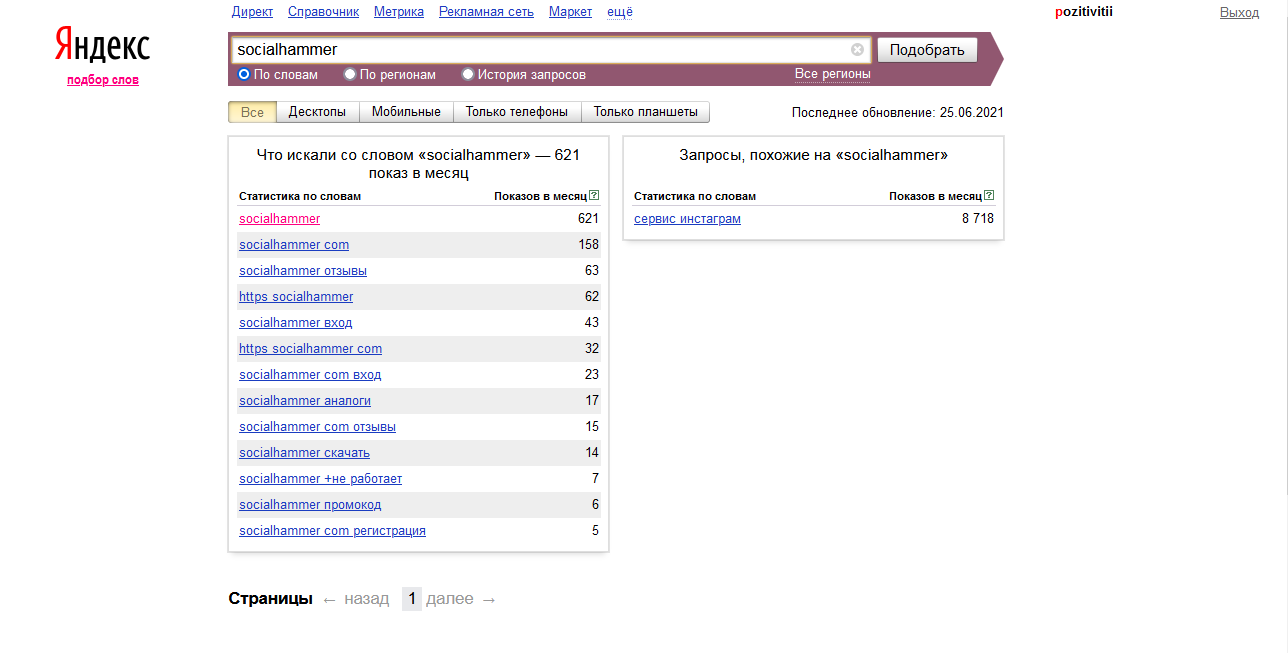
Когда мы создавали семантическое ядро для этой статьи, то получили 529 запросов. В таком случае не обойтись без SEO-инструмента, потому что он поможет сгруппировать фразы и отсеить лишнее. Мы пользовались Key Collector.
1.1 Записываем ключевые запросы и парсим
Задача такая: думаем, что пользователь вводит в строку “Гугла” или “Яндекса”, когда хочет найти статью. Прописываем это в поле для фраз.
Вводим все запросы, которые приходят в голову. Например, мы записали вот такие ключи, когда собирали семантическое ядро для этого материала:
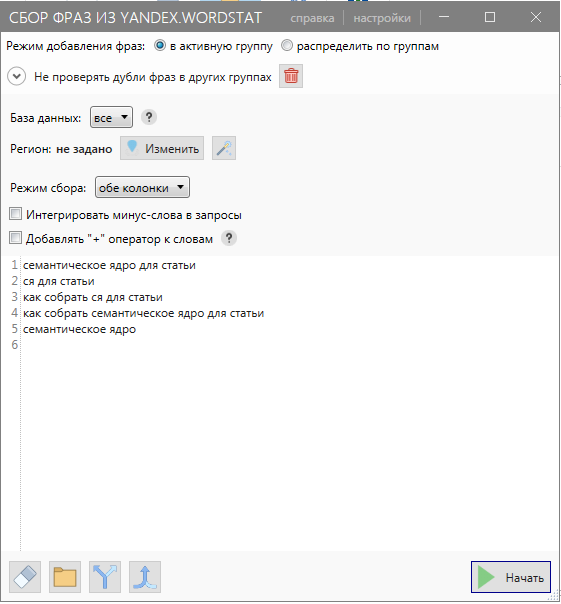
Кликаем “Начать”. Key Collector начнет сбор ключевых фраз из “Яндекс.Вордстата”. Как долго будет длиться парсинг, зависит от количества введенных ключей. Есть способ ускорить процесс – создать несколько потоков и для каждого из них настроить прокси, но это решение подходит, если мы будем собирать ядро для сайта. В этом случае процесс будет долгим. А если парсим запросы для статьи, то полчаса максимум – и все готово.
1.3 Удаляем лишнее
Сейчас наша задача – избавиться от неявных дублей и мусора. Делать это придется вручную, потому что ни одна программа не проведет чистку семантического ядра от всех ненужных запросов.
Алгоритм такой:
1. Заходим на главную страницу и кликаем “Неявные дубли”.
2. Выбираем “Найти”. Алгоритм удалит одинаковые фразы, только с разным порядком слов.
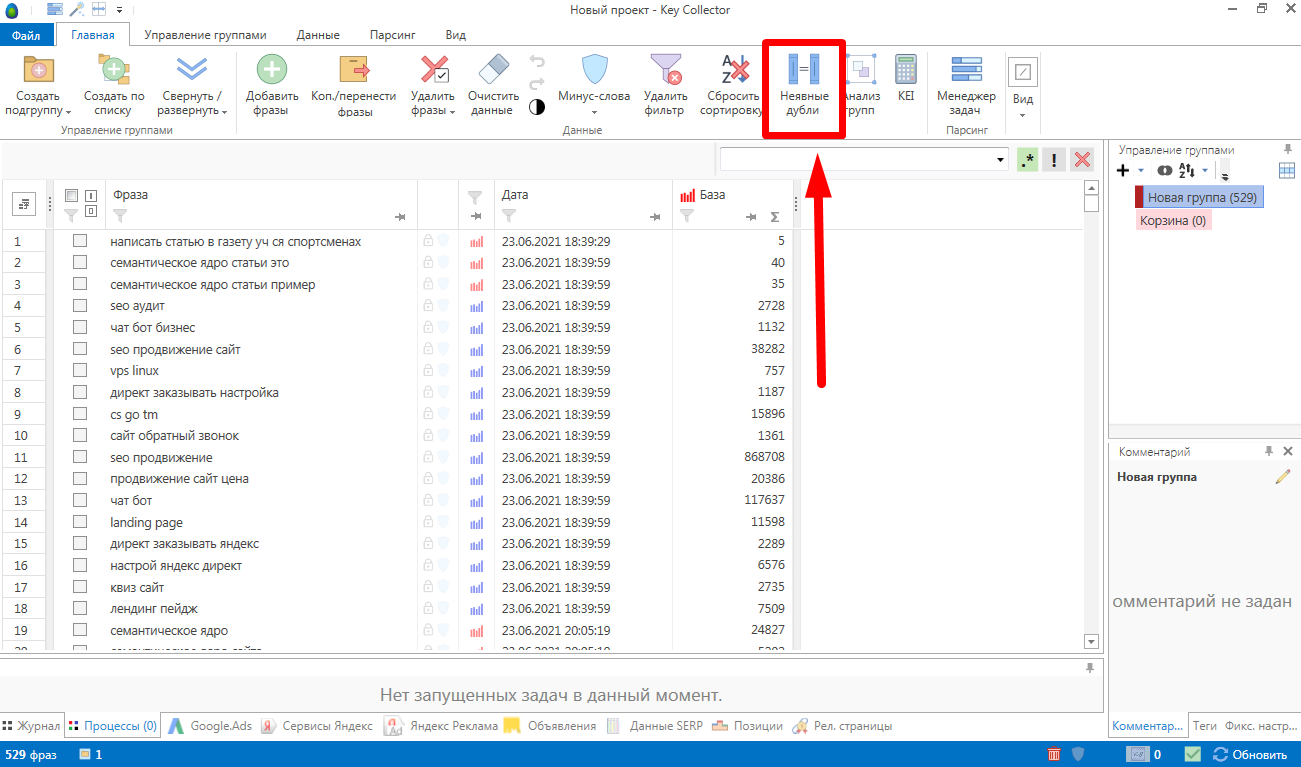
2. Выбираем “Найти”. Алгоритм удалит одинаковые фразы, только с разным порядком слов.
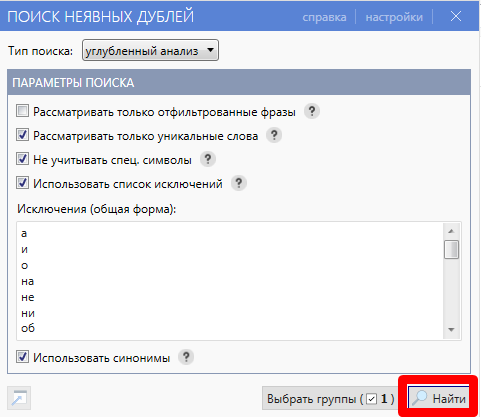
3. Затем кликаем “Минус-слова” и вводим их. Это должны быть ключевые слова для коммерческих запросов и просто нерелевантные фразы. Вот пример для нашего случая: торрент, скачать, купить, заказать, база.
4. Нажимаем “Показать найденные фразы”.
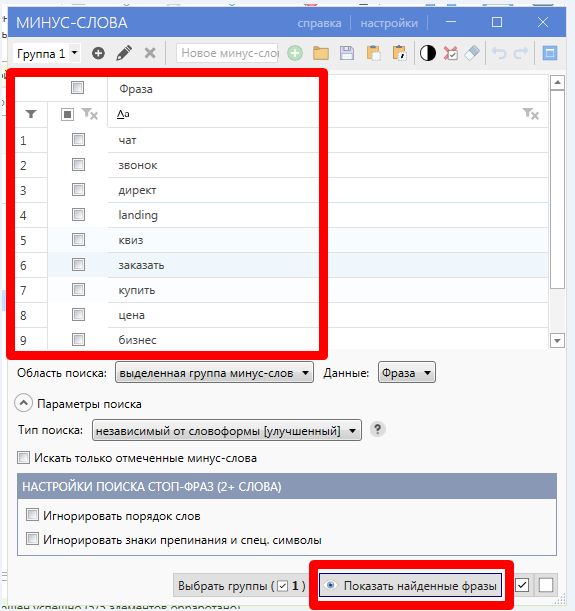
5. Выделяем их все и кликаем “Удалить фразы”.
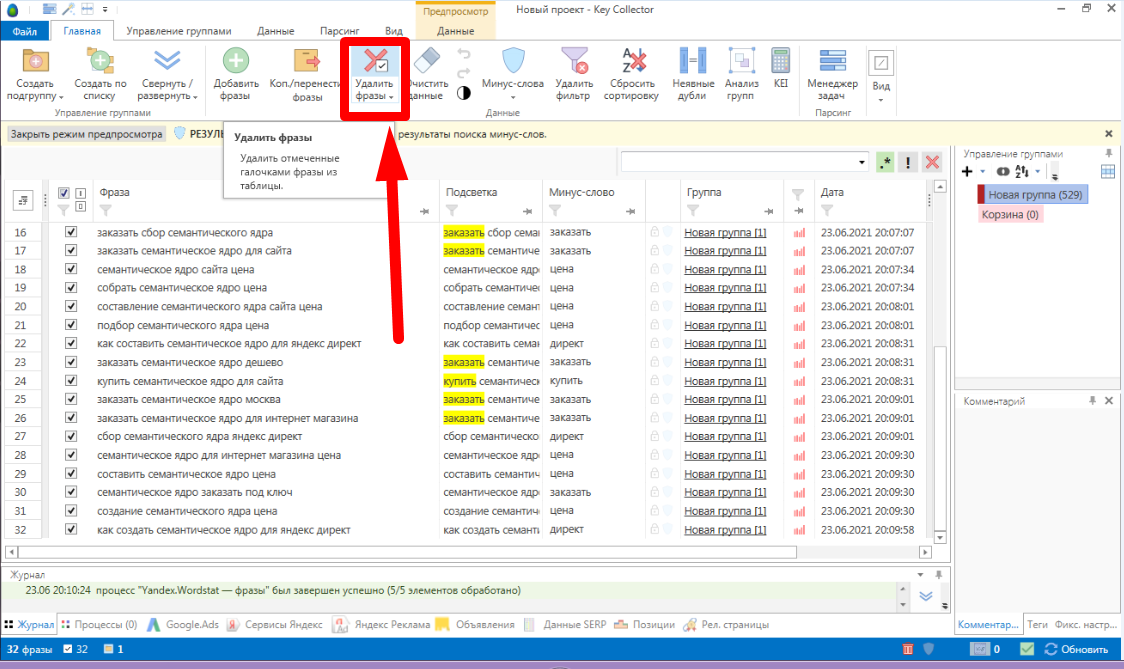
Все. Переходим к следующему шагу.
1.4. Группируем запросы
За один раз все удалить не удастся, какие-то лишние фразочки все равно останутся. К тому же проще выбрать наиболее частотный ключевик из группы одинаковых запросов, чем искать из списка разных.
Можно разбивать запросы на группы вручную, а можно делать это с помощью софта.
Чтобы сгруппировать ключевые запросы в Key Collector, делаем следующее:
- Кликаем “Анализ групп”.
- Выбираем тип группировки “по составу фраз”.
- Нажимаем “Начать анализ”.
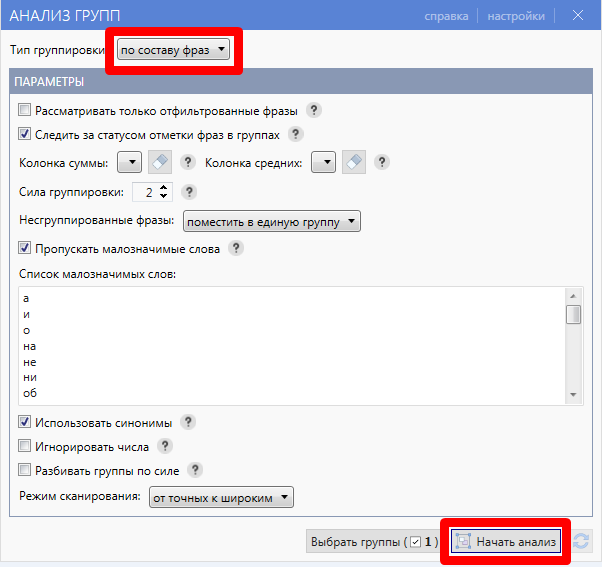
Ждем, пока “Кей Коллектор” проанализирует ключи и отсортирует их.
1.5 Отбираем ключи
Что у нас получилось:
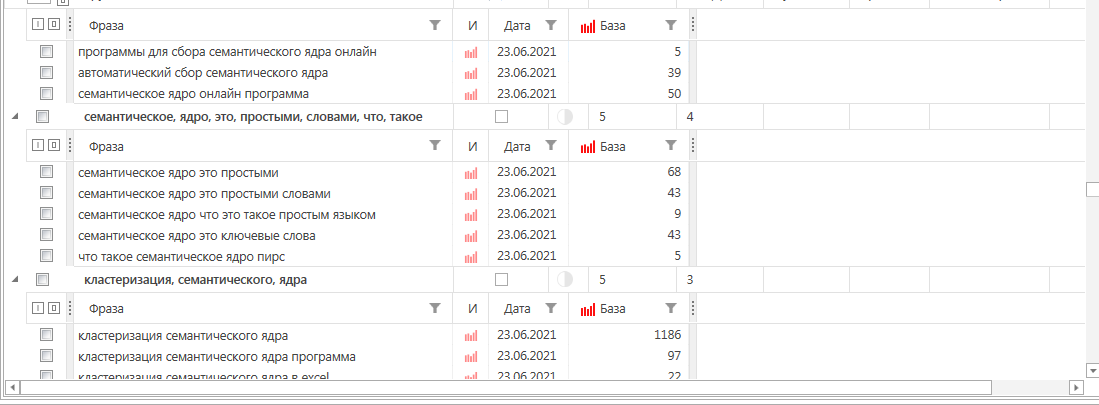
Мы собрали запросы по фразам и сгруппировали их. Теперь опять отсеиваем мусорные. Это делается за пару минут.
После этого начинаем отбирать ключи.
А они нужны?
Есть множество SEO-теорий, и все они противоречат друг другу. Кто-то вообще говорит, что сео-ниша отмирает, поэтому нет смысла трудиться над оптимизацией контента. Кто-то до сих пор применяет тактику 2010-х годов: старается впихнуть как можно больше вхождений в текст с уверенностью, что страница выйдет в топ.
Ни один из подходов уже не работает. Поисковики “научились” определять, отвечает ли текст на вопросы пользователя и является ли он полезным. Но если в нем нет ключей, никакая навороченная система не выставит страницу в топ выдачи, потому что не будет знать, о чем она.
Сколько ключей должно быть в статье?
Точного ответа на этот вопрос нет. Его не даст ни один сеошник. Количество ключей зависит от размера статьи, но точной цифры нет.
Есть только цифра в процентах – ключевых фраз должно быть не больше 4% от всего текста. Проверить плотность вхождений можно здесь.
Обратите внимание: если у вас статья на 3000 символов без пробелов, 7 ключей – это явный перебор. Трех-пяти будет достаточно. То есть количество ключей варьируется от текста к тексту.
Как подбирать ключи к статье
В тексте должны быть:
- высокочастотные запросы (ВЧ);
- среднечастотные запросы (СЧ);
- низкочастотные запросы (НЧ).
Как понять, сколько каких ключей должно быть? Держите таблицу с конкретными числами. Числа взяты для статьи размером 3000 знаков без пробелов.
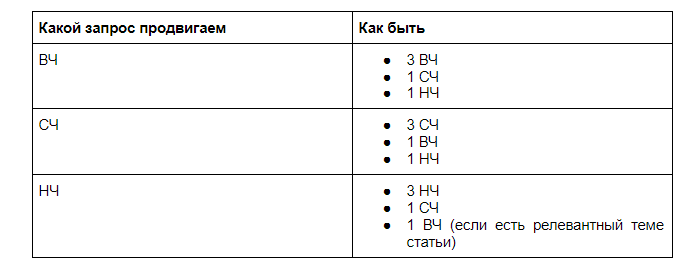
Опять же: каждая статья разная. И если вы продвигаете страницу по среднечастотному запросу, необязательно найдется релевантный низкочастотник.
1.6 Улучшаем морфологическую вариативность
Чтобы собрать семантику для статьи, мало только нахватать ключей из KK. В SEO есть еще понятие морфологическая вариативность. Она включает в себя следующие компоненты:
- синонимы;
- слова из подсветки;
- сленг.
Дело в том, что поисковые системы содержат эталоны текстов по всем тематикам. Например, если вы клепаете статью на тему “Как писать эссе на английском языке”, то Google и Яндекс будут сравнивать ее со своими эталонными текстами. Если ваш труд не соответствует их образцам, он не выйдет в топ.
Если вы вставили ключи в материал, но не видите его на первой странице – поработайте над морфологической вариативностью.
1.6.1 Хвосты
Хвосты в SEO – это слова и фразы, которые не содержат ключевого запроса, но являются релевантными для данной темы. Хвосты могут иметься как до запроса, так и после него. Они появляются в виде подсказок, когда вы вводите ключ в поисковой строке. Подсказки подскажут вам, какие микротемы добавить в статью.
Пример. Вы трудитесь над текстом “Как варить овсяную кашу”. Чтобы узнать, что пользователи хотят увидеть, впишите запрос. Увидите следующее:
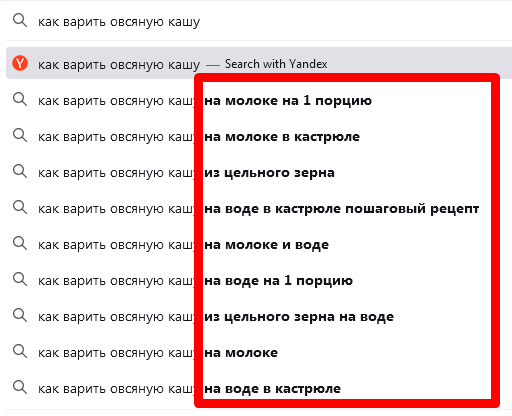
Какие-то хвосты попадут в подзаголовки, какие-то – в текст. Допустим, подзаголовки могут быть вот такие:

1.6.2 LSI-слова
LSI-слова связаны с темой статьи по смыслу. Это сленг и синонимы – слова, которые используют эксперты своей ниши.
Где их искать? Здесь несколько вариантов:
- находим в Key Collector/Яндекс.Вордстат/Just-Magic;
- ищем синонимы и сленг в интернете;
- узнаем синонимы и сленг у профи по тематике материала.
Благодаря lsi-словам поисковик определит, что статью пишет эксперт. Попросите арбитражника настрочить текст о том, как создавать креативы, и сравните с текстом копирайтера, который далек от арбитража. Даже если заказать текст не на бирже и заплатить достаточно – вы увидите разницу. Статья арбитрана с большей вероятностью выйдет в топ, потому что в ней содержатся профессионализмы.
Или другой пример. Статью с синонимическим рядом жесткий диск – винчестер – винт – HDD – SSD вы с большей вероятностью увидите на первой странице, чем текст с одним только словосочетанием “жесткий диск”.
Опять же: не используем lsi-фразы бездумно. Лучше не вставить одно слово в текст, чем неуместно впихнуть и попасть под фильтры поисковиков за некачественный контент.
Как узнать, какие хвосты и лси-слова добавить в материал
Если вы без понятия, как еще покрутить слова и фразы в тексте, обратитесь к сервису Ahrefs. Он проанализирует конкурентов и скажет, что еще добавить в статью и что убрать.
2 Распределяем запросы
Теперь, когда ядро собрано, остается распределить ключевые запросы по тексту. Мы уже частично описали некоторые правила выше. Резюмируем:
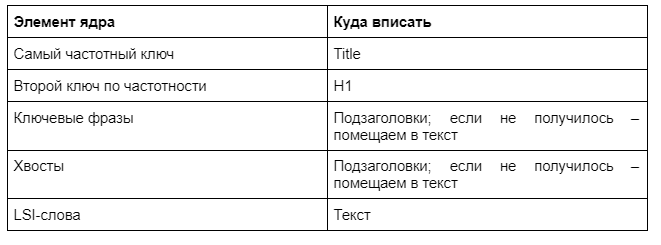
О тайтле и дескрипшине – ниже.
3. Прописываем Title и H1
Самый высокочастотный ключ должен быть в Title. Как выбрать ВЧ? Посмотреть на частоту. Например, вот три самых популярных запроса для нашего материала:
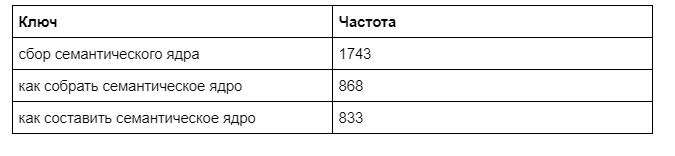
В Title пойдет первый ключ. В H1 – второй.
Затем добавляем хвосты. В нашем случае хвост – “для статьи”. Он должен быть и в тайтле, и в хедлайне. Так как у нас инструкция на примере Key Collector 4, то прописываем это в title. Это нужно для того, чтобы пользователь не тратил свое время. Например, он хочет посмотреть процесс сбора семантического ядра в Яндекс.Wordstat, открывает статью – а там инструкция в КК. Человек сразу же закроет сайт и пойдет на другой ресурс.
Такое случится еще не один раз: ведь юзеров в интернете огромное количество. Если пользователи регулярно заходят на сайт и уходят через пару секунд, поисковые системы начинают считать контент на странице некачественным. Итог – снижаются позиции в выдаче.
4. Прописываем description
В дескрипшене рассказываем, о чем материал. Вставляем ВЧ и СЧ ключи и хвосты. Следите за тем, чтобы description не получился слишком спамным, как здесь:

А как лучше переделать это дескрипшн? Хотя бы так:

5. Необязательно: пишем комментарии
Если по какой-то причине не получилось вместить один ключевой запрос в статью, эта проблема решается. Делаем так: регистрируемся на сайте и оставляем осмысленный комментарий под текстом, при этом используем в комменте нужный ключ.
Сделайте это сами или наймите для этого людей – как вам больше удобно.
Заключение
Итак, правильное СЯ состоит из следующих вещей: ключевых запросов, хвостов и lsi-фраз. Но грамотно составить семантическое ядро – не залог успеха: важно еще распределить элементы ядра по тексту.
Проверяйте статью на переспам. Если страница так и не вышла в топ, а все ключи есть, поработайте над морфологической активностью. Когда набьете руку, то будете знать, какие хвосты раскидывать по подзаголовкам, какой дескрипшен написать, как не переборщить с lsi-словами, и так далее.







